Rui: The Ongoing Battle Against Scam Campaigns on Discord
Rui’s Origin: A Personal Tool for Tracking Data
I didn’t set out to build a Discord bot. With all the health challenges I’ve faced, one pattern became clear: improvement was always preceded by data collection. I discovered I had Circadian Rhythm Disorder because I started tracking my sleep. Instead of trying to explain my experience to a doctor, I could show them a graph:
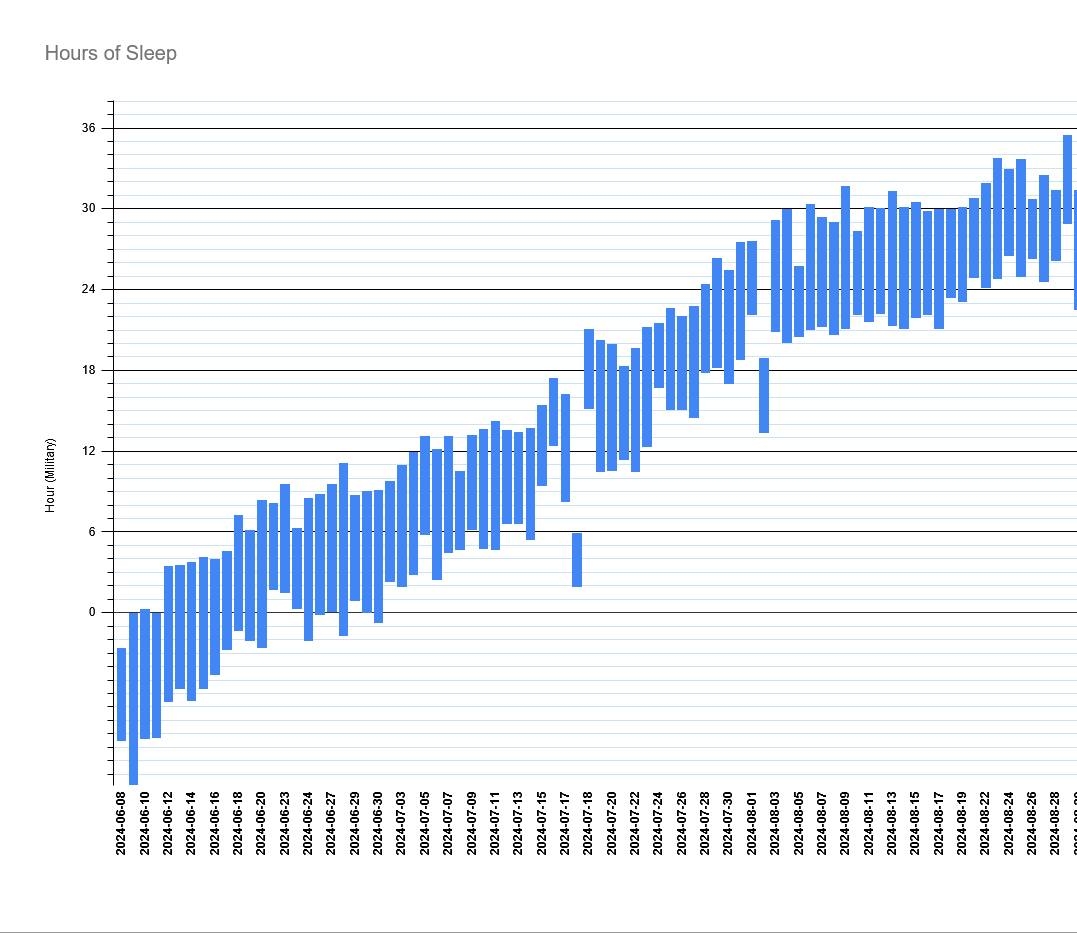
That graph changed the course of my life! It turned something subjective and hard to describe into something concrete and undeniable. Given the other health challenges I face, I wanted a way to track important data with as little friction as possible. The solution I arrived at was a Discord bot that let me log events with a simple slash command:
- When and what I eat
- When I sleep
- Medication changes
- Mood and symptoms
- Accomplishments
Rui started as a deeply personal tool designed to make data collection effortless. At the time, Rui had nothing to do with scam detection. That came later.
The Problem: One Account, Every Channel
I moderate a handful of Discord servers of varying sizes. All of them have experienced periodic disturbances from scammers posting the same message in every channel. Sometimes this would happen while I was sleeping, allowing the scam to spread unchecked. At the time, Discord’s feature to delete a user’s recent messages when banning them would sometimes fail, making cleanup tedious and time-consuming. I had to go into each channel individually and clean up the mess by hand.
After doing this for the third or fourth time, I began to think: “I have a Discord bot… I can do something about this!”
By the time Rui was first taking shape, LLMs had already become the default solution for almost every problem. It would have been natural to reach for one to detect scam messages. But I’m a bit old-fashioned and tend to trust ingenuity and algorithms more than statistical soup. The key observation is that these scam campaigns exhibit abnormal and targetable behavior: they post the same message in every channel, not just once. Their effectiveness comes from automation: they can blast the same message across an entire server in seconds without spending their own time doing it. Even if only one person out of hundreds falls for it, the campaign is still profitable.
Discord has rich text-based automatic moderation features. When you enable Discord Community on your server, you gain access to a sophisticated automod system that can combat single channel spam and flag common spam formats. It even lets you set up regex filters for anything else. Because of this, scammers have moved from sending links and text messages to sending screenshots, which cannot be targeted by automod.
Their strength is automation. Their weakness is repetition.
The First Attempt: Simple Hash Matching
The first version of scam detection was straightforward: compute an MD5 hash of each message and attachment, and compare those hashes against recent messages from the same user. If the same hashes appeared in multiple channels within a short window, it was likely a scam campaign. MD5 was a natural starting point—it’s simple, widely available, and one of the first hashing algorithms most developers encounter. But it was designed for cryptographic integrity at a time when that meant different tradeoffs, and it shows its age: it is slower than modern alternatives and has well-documented collision vulnerabilities that make it unsuitable even for its original purpose. It offered guarantees Rui didn’t need, while failing to deliver the performance Rui required.
When cryptographic security isn’t required, non-cryptographic hash functions provide dramatically better performance while still producing reliable fingerprints. Switching to xxHash made an immediate difference. xxHash is designed for speed. In local benchmarks on a DigitalOcean droplet running Python 3.13.5, hashing a 50 MB attachment took roughly 1.6 milliseconds—faster than thread scheduling overhead in CPython. This helped, but it didn’t solve the deeper problem. The bottleneck wasn’t just the hash function, it was the architecture. Detection was still running on the same event loop as everything else. Every message Rui analyzed delayed other tasks.
Converging on the Right Architecture
When scam detection was added, it ran in the same event loop as everything else. Rui was built using Python’s asynchronous programming model, where a single event loop coordinates all tasks. Coroutines cooperate by voluntarily yielding control, allowing concurrency without parallel execution. I offloaded the hash computation itself to a worker thread, but the detection pipeline still lived within the event loop—each message required scheduling work, awaiting results, and updating internal state, with the event loop responsible for coordinating every step.
This worked, but it introduced a new problem: Rui was no longer as responsive as it used to be, even while running in only a handful of servers—the ones I personally moderated and used for testing. Coming from a C++ background, where multithreading is the default tool for separating workloads, this felt like a natural limitation to work around rather than a design constraint to embrace. If Rui was going to scale beyond my personal use, this architecture wouldn’t hold. Scam detection needed to run without interfering with the responsiveness of user-facing commands.
The Original OOP Event Override Model
My original implementation was built on top of discord.py, which exposes Discord events like on_ready and on_message as coroutine hooks. Rather than binding all logic directly to those hooks, Rui treated the Discord client as shared context and passed it into a set of modules. Each module could override event handlers, and Rui would forward incoming events to every registered module. This effectively created a second dispatch layer on top of discord.py’s native event system. The implementation looked something like this:
class RuiContext:
def __init__(self, client: discord.Client, slash_tree: discord.app_commands.CommandTree):
self.client = client
self.slash_tree = slash_tree
class RuiModule:
def __init__(self, context: RuiContext, **kwargs):
self.context = context
self.initialize(**kwargs)
# Hook for modules to bind commands or set-up external API state before discord.client is initialized
def initialize(self, **kwargs):
pass
# Hook for modules to bind to discord.client.event.on_ready
async def on_ready(self):
pass
# Hook for modules to bind to discord.client.event.on_message
async def on_message(self, message: discord.Message):
pass
class SpamGuard(RuiModule):
def initialize(self, **kwargs):
self.buffer = deque()
async def on_message(self, message : discord.Message):
message_hash = await SpamGuard.hash_message(message.content)
# etc
modules: List[RuiModule] = [
RootTasks(context),
SpamGuard(context)
]
# Event Bindings
@context.client.event
async def on_ready():
await context.slash_tree.sync(guild=None)
for module in modules:
await module.on_ready()
print(f"Rui is online as {context.client.user}")
@context.client.event
async def on_message(message: discord.Message):
# Ignore messages Rui sent
if message.author == context.client.user:
return
for module in modules:
await module.on_message(message)
This design made Rui modular. Features could be added as independent components without modifying the core event loop. SpamGuard, my personal logging commands, and other functionality all lived side by side as peers in the same system. It also made Rui easy to reason about: each module owned its own state and reacted to events independently, without needing to know about other modules.
However, this architecture came with tradeoffs. Features were tightly coupled to the RuiModule contract, and extending Rui sometimes meant modifying the base class itself. As the system grew, the abstraction began to leak, and changes intended for one module could unintentionally affect others. What had started as a clean separation of concerns became a shared execution surface.
Another key challenge was event fan-out. Every incoming message was forwarded to every module, and all of that work was coordinated by the same event loop. Even if individual operations were offloaded to worker threads, the event loop still had to schedule and await each step. As Rui grew, the amount of work performed for each message increased. SpamGuard was no longer just observing events — it was adding measurable overhead to Rui’s core execution flow.
Moving to a Multithreaded Architecture
As I mentioned earlier, I am more of a C++ developer and think in terms of threads. The single event loop model made all workloads compete for the same execution time, even when their priorities were very different. Slash commands needed to be responsive, statistics needed to be recorded at precise intervals, while spam detection and configuration updates could tolerate some delay. These workloads had fundamentally different latency requirements, but the single event loop forced them to compete equally.
My first architectural shift was to isolate major subsystems into separate threads, each running its own asynchronous event loop. Message processing, slash commands, error reporting, configuration updates, and statistics aggregation were all separated. This ensured that delays in one subsystem would not interfere with others.
The entry point for this architecture looked like this:
main.py
import asyncio
import threading
from collections.abc import Callable, Awaitable
from procs.commands import main as commands
from procs.config import main as config
from procs.errors import main as errors
from procs.messages import main as messages
from procs.stats import main as stats
def target_thread(ready: threading.Event, main: Callable[[threading.Event], Awaitable[None]]):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(main(ready))
async def run(main: Callable[[threading.Event], Awaitable[None]], timeout: float, label: str):
ready = threading.Event()
thread = threading.Thread(
target=target_thread,
args=(ready, main),
daemon=True
)
thread.start()
if not ready.wait(timeout=timeout):
raise RuntimeError(f"{label} failed to initialize in a timely manner")
print(f"{label} Initialized")
async def main():
await run(errors, 5, "Error Handler")
await run(config, 5, "Mongo Listener")
await run(stats, 5, "Statistics Aggregator")
await run(commands, 5, "Commands Module")
await run(messages, 5, "Messages Module")
if __name__ == '__main__':
asyncio.run(main())
Each subsystem ran in its own thread, with its own event loop and isolated runtime. The commands thread handled slash commands and user interaction. The messages thread handled spam detection and message analysis. The errors thread monitored exceptions and reported them to me via direct message. The stats thread aggregated metrics on a fixed schedule, and the config thread ran an HTTP server that allowed Rui’s web dashboard to notify the bot when server settings changed.
As an example, the messages subsystem looked like this:
procs/messages.py
import discord
import threading
from dataclasses import dataclass
from collections.abc import Callable, Awaitable
from procs.errors import report_exception
@dataclass
class RuiMessageHandler:
name: str
on_ready: Callable[[], Awaitable[None]]
on_message: Callable[[discord.Message], Awaitable[None]]
async def main(ready: threading.Event):
INTENTS = discord.Intents.default()
INTENTS.message_content = True
INTENTS.guilds = True
INTENTS.messages = True
INTENTS.members = True
discord_client = discord.Client(intents=INTENTS)
from modules.scam_guard import register as scam_guard
handlers: list[RuiMessageHandler] = [
scam_guard(discord_client)
]
@discord_client.event
async def on_ready():
for handler in handlers:
await handler.on_ready()
ready.set()
@discord_client.event
async def on_message(message: discord.Message):
# Ignore messages Rui sent
if message.author == discord_client.user: return
for handler in handlers:
try:
await handler.on_message(message)
except Exception as err:
report_exception(f"{handler.name}.on_message", err)
from utils.discord import start
await start(discord_client)
Each subsystem followed the same pattern: its own Discord client, its own event loop, and its own isolated execution environment.
This separation solved the original responsiveness problem. Spam detection could run as slowly as needed without affecting command responsiveness. Background tasks like statistics collection and configuration updates no longer competed with user-facing functionality. However, this introduced new problems.
Each thread required its own Discord client, which meant maintaining multiple independent gateway sessions. Every client introduced its own heartbeat, event stream, and rate limit pressure, multiplying gateway load and increasing memory usage. Even at Rui’s small scale — just a handful of guilds — this architecture was already hitting Discord’s API and gateway limits. The system wasn’t merely inefficient; it was fundamentally incompatible with sustainable operation.
Sharing state between subsystems also had to follow careful, deliberate contracts. Each thread had its own event loop and its own Discord client, which meant asynchronous state could not be shared directly. Communication between subsystems, such as error reporting, required crossing event loop boundaries. This added coordination overhead and reduced architectural flexibility.
This architecture solved the responsiveness problem, but it did so by fragmenting Rui into loosely connected subsystems. It increased operational complexity, introduced synchronization challenges, and consumed more system and API resources than anticipated. It was clear that I had traded one set of constraints for another, and that threading alone was not the right long-term architecture for Rui.
Hitting Memory Limits and Profiling Failures
At this point, I was thinking seriously about Rui’s scalability and what it would cost to operate at larger scale. If Rui was going to grow beyond my personal use, I needed to understand how much memory each guild consumed. My scam detection pipeline stored audit state for every intercepted message, and those structures were designed for correctness and traceability, not efficiency. At the time, they looked like this:
@dataclass(frozen=True)
class AttachmentFingerprint:
filename: str
content_type: str # e.g., "image/png"
size: int
hash: str | None # None if too large to hash
@dataclass
class InterceptedMessage:
id: int = field(compare=False)
user: int
guild: int
channel: int = field(compare=False)
hashed_message: str
attachment_fingerprints: Counter[AttachmentFingerprint]
class InterceptedCounter:
def __init__(self):
self.messages: list[InterceptedMessage] = []
self.deleted: list[InterceptedMessage] = []
self.guild_counts: Counter[int] = Counter()
self.channel_counts: Counter[int] = Counter()
def add(self, msg: InterceptedMessage):
self.messages.append(msg)
self.guild_counts[msg.guild] += 1
self.channel_counts[msg.channel] += 1
self.guilds = ', '.join([MENTION_GUILD(gid) if count == 1 else f"{MENTION_GUILD(gid)} (x{count})" for gid, count in self.guild_counts.items()])
self.channels = ', '.join([MENTION_CHANNEL(cid) if count == 1 else f"{MENTION_CHANNEL(cid)} (x{count})" for cid, count in self.channel_counts.items()])
@dataclass
class InterceptedAudit:
identifier: str
counter: InterceptedCounter = field(default_factory=InterceptedCounter, compare=False)
quarantined: bool | None = field(default=None, compare=False)
reported: int | None = field(default=None, compare=False)
alerted: set[int] = field(default_factory=set, compare=False)
audited: int | None = field(default=None, compare=False)
networked: list[int] = field(default_factory=list, compare=False)
user: int | None = field(default=None, compare=False)
message: str | None = field(default=None, compare=False)
attachment_data: dict[AttachmentFingerprint, bytes | None] = field(default_factory=dict, compare=False)
@dataclass
class MessageLog:
timestamp: datetime = field(compare=False)
message: InterceptedMessage
audit: InterceptedAudit = field(compare=False)
This design made audits easy to reason about. Each intercepted message carried its own structured metadata, and audit state preserved everything needed to reconstruct what had happened. However, this came at a cost. These objects formed deep reference graphs, and audit state accumulated quickly under sustained message volume.
To understand how serious the problem was, I wrote a recursive memory profiler to measure the true footprint of these structures:
def sizeof(obj, seen=None) -> int:
"""Recursively calculate size of an object and its references"""
if seen is None:
seen = set()
obj_id = id(obj) # Unique memory address
if obj_id in seen:
return 0 # Already counted this object
seen.add(obj_id)
size = sys.getsizeof(obj) # Size of this object itself
# Now figure out what this object points to:
# 1. If it's a dict, recurse on keys and values
if isinstance(obj, dict):
size += sum(sizeof(k, seen) + sizeof(v, seen) for k, v in obj.items())
# 2. If it has __dict__ (custom class instances), recurse on that
elif hasattr(obj, '__dict__'):
size += sizeof(obj.__dict__, seen)
# 3. If it's iterable (list, tuple, deque, set), recurse on contents
elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
try:
size += sum(sizeof(item, seen) for item in obj)
except TypeError:
pass # Some iterables can't be iterated (like iterators that are exhausted)
# 4. If it has __slots__, we'd need to handle that too (I don't think I do)
return size
This function walks the full object graph, recursively measuring the size of dictionaries, lists, and custom objects while avoiding double-counting shared references.
It was useful — and dangerous.
The irony is that the profiler itself could be heavier than the data it was measuring. The seen set grows with every object visited, and the recursive traversal adds stack frames and temporary allocations. On large buffers, that overhead could dominate the measurement and create memory spikes that looked like the system was ballooning, when in reality the profiler was doing most of the ballooning.
The underlying data structures still had more overhead than they needed, and this profiling exercise made that visible. It also pushed me toward redesigning Rui around simpler, leaner structures that could self report their memory usage efficiently, which reduced the steady-state memory footprint by roughly 30%.
Redesigning Data Structures for Efficiency
The original audit structures were designed for correctness and traceability, not memory efficiency. They relied heavily on dictionaries, counters, and nested containers. While convenient, these abstractions carry significant hidden overhead. Every object stored its attributes in a per-instance dictionary, and every container introduced additional allocation, hashing, and bookkeeping costs.
To reduce this overhead, I redesigned Rui’s core data structures as immutable, fixed-layout value objects:
@dataclass(frozen=True, eq=False, slots=True)
class AttachmentFingerprint:
filename: str
content_type: str
size: int
xhash: int | None
phash: str | None
_memory_size: int = field(init=False)
@dataclass(frozen=True, eq=False, slots=True)
class MessageFingerprint:
xhash: int
shash: int
urlish: bool
attachments: tuple[AttachmentFingerprint, ...]
_memory_size: int = field(init=False)
@dataclass(frozen=True, slots=True)
class InterceptedAt:
timestamp: datetime
message_id: int
user_id: int
guild_id: int
channel_id: int
_memory_size: int = field(init=False)
@dataclass(frozen=True, slots=True)
class MessageLog:
whence: InterceptedAt
fingerprint: MessageFingerprint
_memory_size: int = field(init=False)
These structures use three important design choices:
slots=Trueeliminates the per-instance dict, reducing memory overhead and improving locality.frozen=Truemakes each object immutable, ensuring its memory footprint never changes after creation.- Tuples instead of dynamic containers ensure predictable, compact layouts without hash table overhead.
Together, these changes flattened Rui’s audit structures into a compact tree of immutable value objects with minimal allocator overhead. However, these fingerprint and log objects do not exist in isolation. They are organized into higher-level runtime structures that track active scam investigations and recent message history on a per-guild basis:
@dataclass(eq=False, slots=True)
class Quarantine:
user_id: int
confidence: float
raw: RawMessage
reference: MessageLog
comparisons: set[MessageLog]
decisions: dict[MessageLog, MatchDecision]
actionable_channels: set[int]
_counter: float = field(init=False)
_task: asyncio.Task = field(init=False)
@dataclass(eq=False, slots=True)
class Monitor:
active_quarantines: dict[int, Quarantine] = field(default_factory=dict)
message_window: deque[MessageLog] = field(default_factory=deque)
user_index: defaultdict[int, set[MessageLog]] = field(default_factory=lambda: defaultdict(set))
The Monitor acts as the root container for all scam detection state within a guild. It maintains a rolling window of recent messages, indexes messages by user for fast lookup, and tracks active quarantines for suspicious behavior. Because these structures reference immutable MessageLog and MessageFingerprint objects, their memory usage can be computed deterministically by adding their respective _memory_size properties.
Memory Usage as a First-Class Property
Instead of measuring memory externally, each immutable object computes its own footprint during initialization and stores it in _memory_size. Because these structures never change after creation, this value remains valid for the lifetime of the object.
For example, MessageFingerprint computes its total footprint by summing its own size and the sizes of its components:
@dataclass(frozen=True, eq=False, slots=True)
class MessageFingerprint:
xhash: int
shash: int
urlish: bool
attachments: tuple[AttachmentFingerprint, ...]
_memory_size: int = field(init=False)
def __post_init__(self):
# Base size of the instance container
total = sys.getsizeof(self)
total += sys.getsizeof(self.xhash)
total += sys.getsizeof(self.shash)
total += sys.getsizeof(self.urlish)
total += sys.getsizeof(self.attachments)
# Add size of each fingerprint object in the tuple
for attachment in self.attachments:
total += attachment._memory_size
# Add size of the integer object that will be assigned to _memory_size
total += MEMORY_SIZE
object.__setattr__(self, '_memory_size', total)
This transforms memory accounting from an expensive recursive traversal into a simple linear summation of _memory_size across live objects:
def profile_scam_guard() -> Generator[tuple[int | None, int], None, None]:
total_size = sys.getsizeof(context.buffer)
for guild_id, monitor in context.buffer.items():
size = sys.getsizeof(guild_id) + monitor.getsizeof()
yield guild_id, size
total_size += size
yield None, total_size
Memory usage is now observable in real time, without recursion, graph traversal, or profiler overhead.
Transitioning back to a Single-Threaded Async Architecture
My previous architecture worked, but it was fundamentally in conflict with the direction Rui needed to take. The commit message that marked its undoing captures the radical nature of its transition:
Probably the most uncomfortable commit of my life
It was uncomfortable not because it was broken, but because, despite its flaws, it worked. I was performing open-heart surgery on a live system—dismantling a functional architecture and replacing the runtime model at its foundation, without the safety of incremental change.
Running multiple Discord clients across threads was not viable long term—even at just four guilds I was already hitting gateway and API limits. I had optimized for the wrong constraint, and progress necessitated a course correction. The multiple clients, threads, and subsystem boundaries had to collapse back into a single coherent runtime.
There would be one Discord client, one event loop, and one place where events entered the system. It felt like a step backwards in infrastructure, but it was a step forwards in correctness.
I started by switching Discord event handling to an explicit registration model.
discord_client: Final[discord.Client] = discord.Client(intents=intents())
_message_handlers: list[Callable[[discord.Message], Awaitable[None]]] = []
def on_message(handler: Callable[[discord.Message], Awaitable[None]]):
"""Simple decorator allowing multiple bindings for on_message"""
logger.info(f"Adding {handler.__name__} to on_message")
_message_handlers.append(handler)
return handler
@discord_client.event
async def on_message(message):
if _is_shutting_down: return
if message.author == discord_client.user: return
for handler in _message_handlers:
_fire(handler.__name__, handler(message))
Yes, discord_client is a global in my Discord module, and that is intentional. It is accessed frequently, and wrapping it in class state would only add indirection without providing meaningful structure. At import time, functions decorated with @on_message register themselves as handlers. When the Discord event fires, the dispatcher invokes each registered handler in turn.
At this point I also started thinking seriously about graceful shutdown. _fire wraps handlers so uncaught exceptions are reported, and it tracks active tasks so the bot can drain them during shutdown.
async def _guarded(name: str, coro: Awaitable[Any]):
try:
await coro
except Exception as err:
await report_exception(name, err)
def _fire(name: str, coro: Awaitable[Any]):
task = asyncio.create_task(_guarded(name, coro), name=name)
_active_tasks.add(task)
task.add_done_callback(_active_tasks.discard)
async def _drain():
if _active_tasks:
await asyncio.gather(*_active_tasks, return_exceptions=True)
async def discord_stop():
global _is_shutting_down
_is_shutting_down = True
await _drain() # Let active event handlers finish
from components.scam_guard.tracking import drain_quarantines
await drain_quarantines() # Let active quarantines finish
async def discord_shutdown():
await discord_client.close()
if _client_task is not None:
_client_task.cancel()
try:
await _client_task
except asyncio.CancelledError:
pass
It also allows multiple handlers to run concurrently on the event loop, rather than forcing them to execute sequentially. This ensures slow handlers do not block unrelated work, preserving responsiveness while maintaining correctness.
Separating Boot from Runtime
Python’s async model draws a hard line between import time and execution time: there is no running event loop until asyncio.run() starts one. As Rui became more modular, components needed to do async setup—connect to services, register handlers, restore state—and declare background tasks that should run for the lifetime of the process. Those are two different lifecycle phases. I made that explicit with a two-phase scheduler: a boot phase for dependency-ordered initialization, and a daemon phase for long-running background tasks.
@dataclass(eq=False, slots=True)
class BootLoader:
id: int = field(init=False)
func: BOOT_TASK
depends: set[BootLoader]
completed: asyncio.Event = field(default_factory=asyncio.Event, init=False, compare=False, hash=False)
def __post_init__(self):
self.id = context.PRIMARY_KEY
context.PRIMARY_KEY += 1
context.boot_tasks.add(self)
def ready(self):
return all(boot.completed.is_set() for boot in self.depends)
async def exec(self):
result = self.func()
if asyncio.iscoroutine(result):
await result
self.completed.set()
@dataclass(eq=False, slots=True)
class Daemon(ABC):
id: int = field(init=False)
task: DAEMON_TASK
asyncio_task: asyncio.Task[None] | None = field(init=False, default=None)
def __post_init__(self):
self.id = context.PRIMARY_KEY
context.PRIMARY_KEY += 1
context.daemon_tasks.add(self)
@abstractmethod
async def run(self) -> None:
raise NotImplementedError
async def _execute(self, timestamp: datetime) -> None:
try:
await self.task(timestamp)
except Exception as e:
await report_exception(f"{self.__class__.__name__}.{self.task.__name__} task raised exception at {timestamp}", e)
I have two kinds of Daemon which inherit from this class:
IntervalDaemonwhich does a simpleasyncio.sleepbetween callingself._executeBoundaryDaemonwhich waits until the next clock boundary so tasks run at precise, predictable times (for example, exactly at the top of each minute)
And these get created and cataloged by the following function:
@overload
def schedule(func: BOOT_TASK, *, depends: set[BootLoader] | None = None, interval: None = None, boundary: None = None, start_immediately: None = None) -> BootLoader: ...
@overload
def schedule(func: DAEMON_TASK, *, interval: timedelta, start_immediately: bool = False, boundary: None = None, depends: None = None) -> IntervalDaemon: ...
@overload
def schedule(func: DAEMON_TASK, *, boundary: timedelta, interval: None = None, depends: None = None, start_immediately: None = None) -> BoundaryDaemon: ...
def schedule(func: BOOT_TASK | DAEMON_TASK, *, depends: set[BootLoader] | None = None, boundary: timedelta | None = None, interval: timedelta | None = None, start_immediately: bool | None = False) -> BootLoader | IntervalDaemon | BoundaryDaemon:
match (depends, interval, boundary):
case (None, None, None):
return BootLoader(cast(BOOT_TASK, func), set())
case (set() as depends, None, None):
return BootLoader(cast(BOOT_TASK, func), depends)
case (None, timedelta() as interval, None):
return IntervalDaemon(cast(DAEMON_TASK, func), interval, bool(start_immediately))
case (None, None, timedelta() as boundary):
return BoundaryDaemon(cast(DAEMON_TASK, func), boundary)
case _:
raise RuntimeError("schedule(): only one of depends, interval, or boundary may be specified")
At runtime, schedule() just checks which keyword you provided—depends, interval, or boundary—and registers the function as either a boot task or a daemon. The overloads exist purely for the type checker: they make the “exactly one of these modes” contract explicit. schedule() also returns the handle so that boot time functions that must be loaded in a certain order can reference each other such as:
async def wait_for_discord():
global _client_task
_client_task = asyncio.create_task(start_client())
await _ready_event.wait()
async def handle_uncaught():
async def exception_handler(loop, context):
err = context.get('exception') or Exception(context.get('message', 'Unknown error'))
logger.error(f"Uncaught exception: {err}")
await report_exception("Event loop", err)
loop = asyncio.get_event_loop()
loop.set_exception_handler(exception_handler)
DISCORD_READY = schedule(wait_for_discord, depends={CONFIG_LOADED, MONGO_CONNECTED, REDIS_CONNECTED, POSTGRES_CONNECTED})
EXCEPTIONS_READY = schedule(handle_uncaught, depends={DISCORD_READY})
Making Rui Distributed
As Rui’s responsibilities grew, it began competing for resources with the rest of my infrastructure. It was running on the same DigitalOcean droplet as my blog—alongside:
- nginx
- node.js express webserver
- mongo
- postgresql
- redis
- Rui
This arrangement worked initially, but Rui’s workload was fundamentally different from everything else on that machine. Slash commands required low-latency responses and minimal processing, while scam detection required continuous analysis of every message across all guilds. These workloads had different scaling characteristics.
This naturally divided Rui into two architectural roles:
- Control plane — responding to slash commands and aggregating statistics
- Worker plane — processing guild messages and running the scam guard
I moved the worker role onto a separate droplet, allowing message processing to scale independently from the control plane. Each instance is assigned a unique identifier via its configuration file:
- Instance 0: control plane (slash commands, statistics aggregation)
- Instance 1 (and future instances): worker plane (message processing and scam detection)
To allow these instances to operate as a single system, I introduced a private network using Headscale. This allowed all instances to securely share access to MongoDB, PostgreSQL, and Redis without exposing those services publicly.
Redis became the coordination layer. It tracks which instance is responsible for each guild and allows workers to lease and release guild responsibility dynamically. This ensures that each guild is processed by exactly one worker while allowing the system to scale horizontally as more workers are added.
In practice, this level of distribution is unnecessary at Rui’s current scale. A single instance can comfortably handle thousands of guilds. But the architecture now supports horizontal scaling without requiring further structural changes. The only missing piece is a cost model that allows workers to balance load intelligently when leasing guilds.
Preparing Rui for Horizontal Scaling
Splitting Rui into multiple instances introduced a new problem: coordination. Each Discord Server (referred to as guild) must be processed by exactly one worker. If two instances process the same guild, duplicate alerts and inconsistent state could result. If no instance processes a guild, scams would go undetected.
To solve this, I introduced a simple leasing system using Redis. Each instance periodically attempts to claim responsibility for guilds by acquiring short-lived leases. These leases expire automatically if the instance stops renewing them, allowing other instances to take over without manual intervention.
The core of this mechanism is an atomic Redis operation:
local guild_key = KEYS[1]
local instance_id = ARGV[1]
local ttl = tonumber(ARGV[2])
local current = redis.call('get', guild_key)
if current then
return 0
end
redis.call('setex', guild_key, ttl, instance_id)
return 1
This ensures that only one instance can claim a guild at a time. Each instance periodically:
- discovers eligible guilds
- attempts to claim unassigned guilds
- renews leases for guilds it already owns
- releases guilds that are no longer enabled
At present, a single worker instance claims all guilds. This is intentional. The leasing mechanism exists to allow horizontal scaling when needed, but does not introduce complexity prematurely. Additional worker instances can be added without modifying the core architecture.
The system is designed around a capacity abstraction, allowing each instance to limit how many guilds it accepts. At present this limit is fixed, and a single worker instance handles everything comfortably. But because leasing is capacity-driven, scaling horizontally becomes a matter of adding more instances rather than redesigning the system. In the future, capacity will be based on real resource usage such as memory and CPU usage.
Architecture: Sliding Windows and Guild-Scoped Memory
Scam campaigns unfold over very short time horizons. A compromised account will often post the same message across many channels within seconds. This burst of activity is what distinguishes coordinated spam from normal user behavior. Messages sent minutes or hours earlier are no longer relevant to identifying the campaign.
This naturally leads to a sliding window model. Each guild maintains a rolling buffer of recent messages, allowing Rui to observe these bursts as they happen. As new messages arrive, older ones fall out of the window and are discarded. The window exists not as a performance optimization, but because scam campaigns themselves are temporally bounded events.
This state is maintained independently for each guild in the Monitor structure introduced earlier. Each guild has its own rolling message history and active investigations, ensuring detection remains localized and memory usage remains proportional to recent activity rather than total lifetime activity.
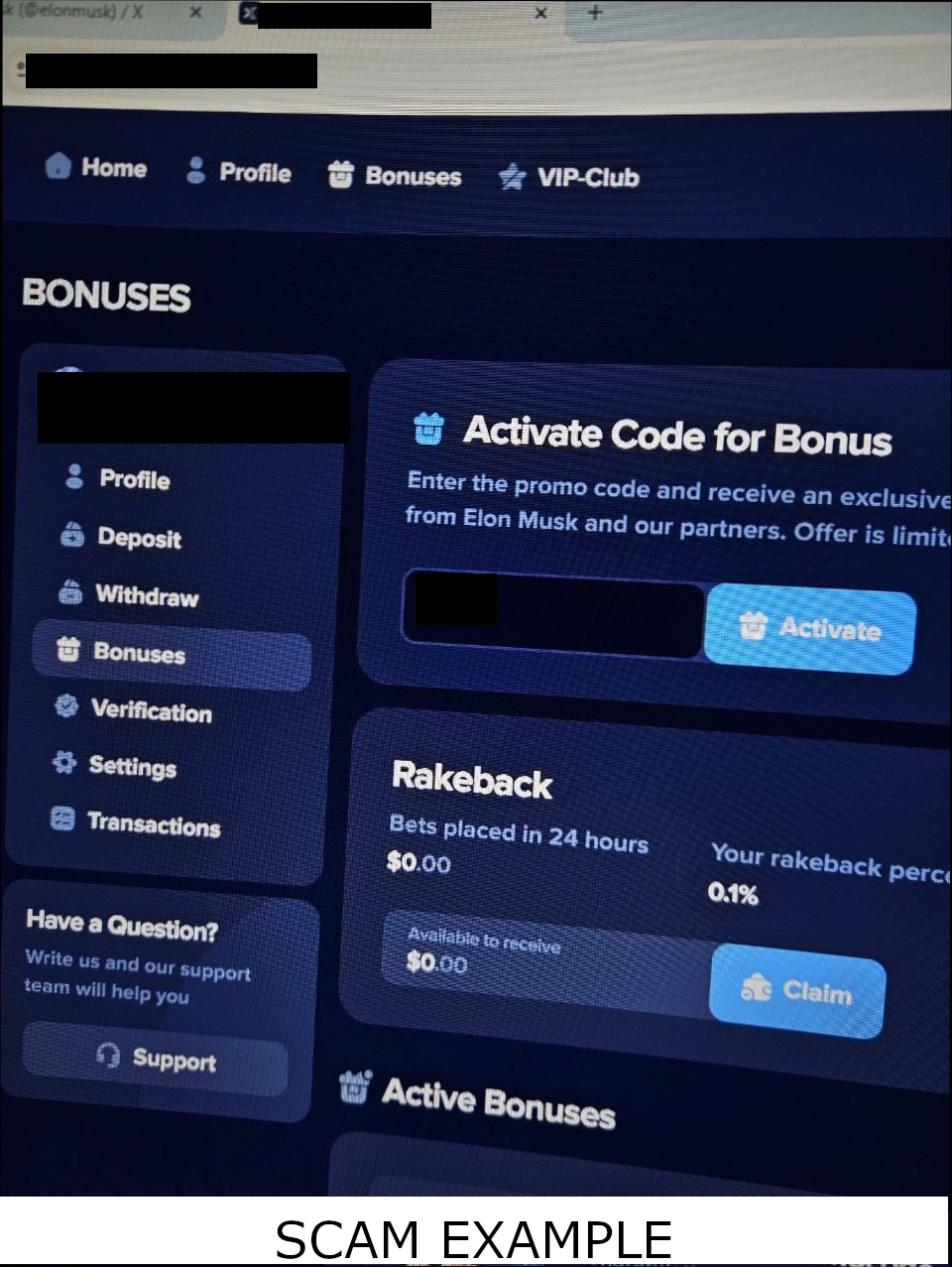
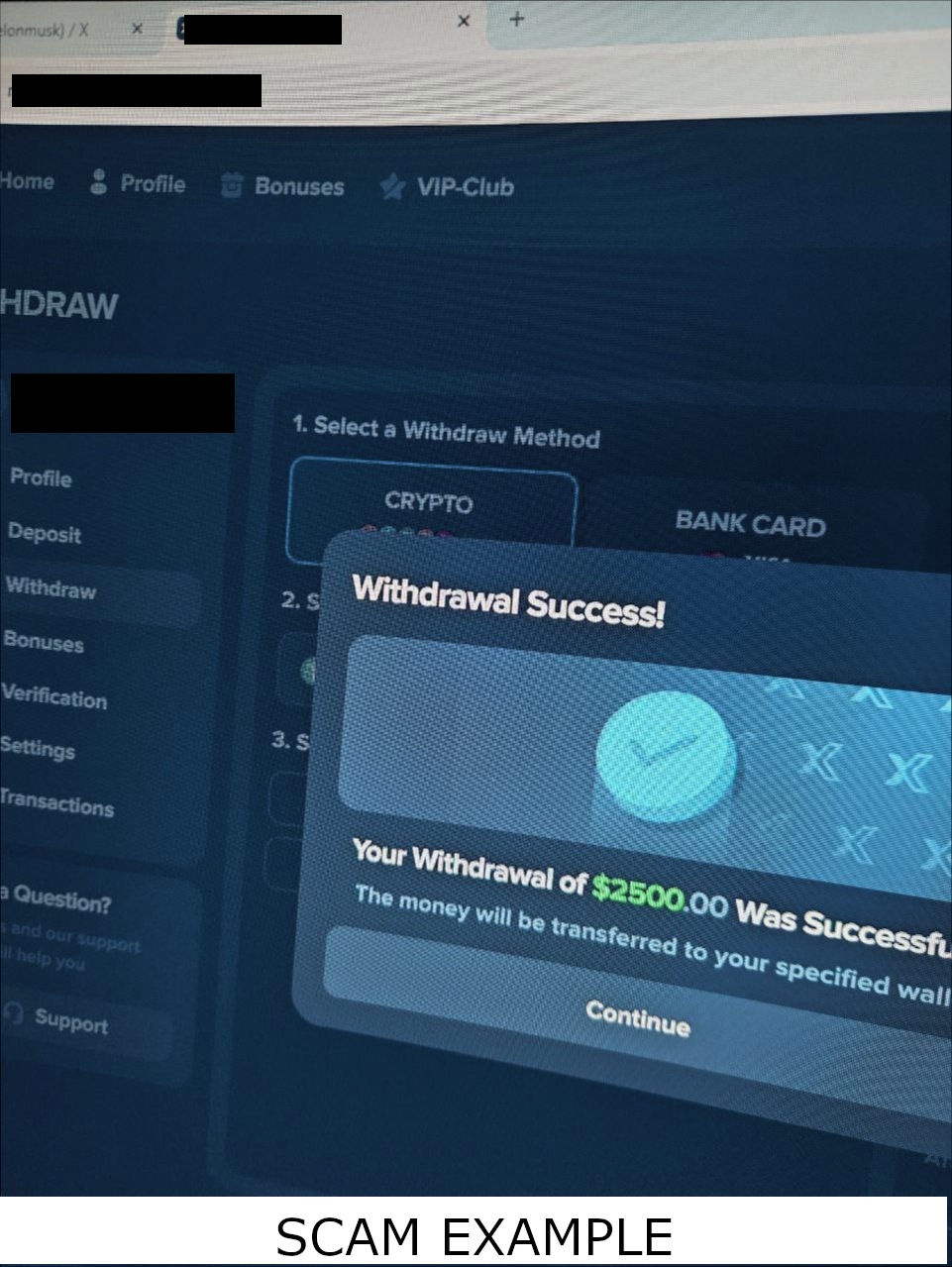
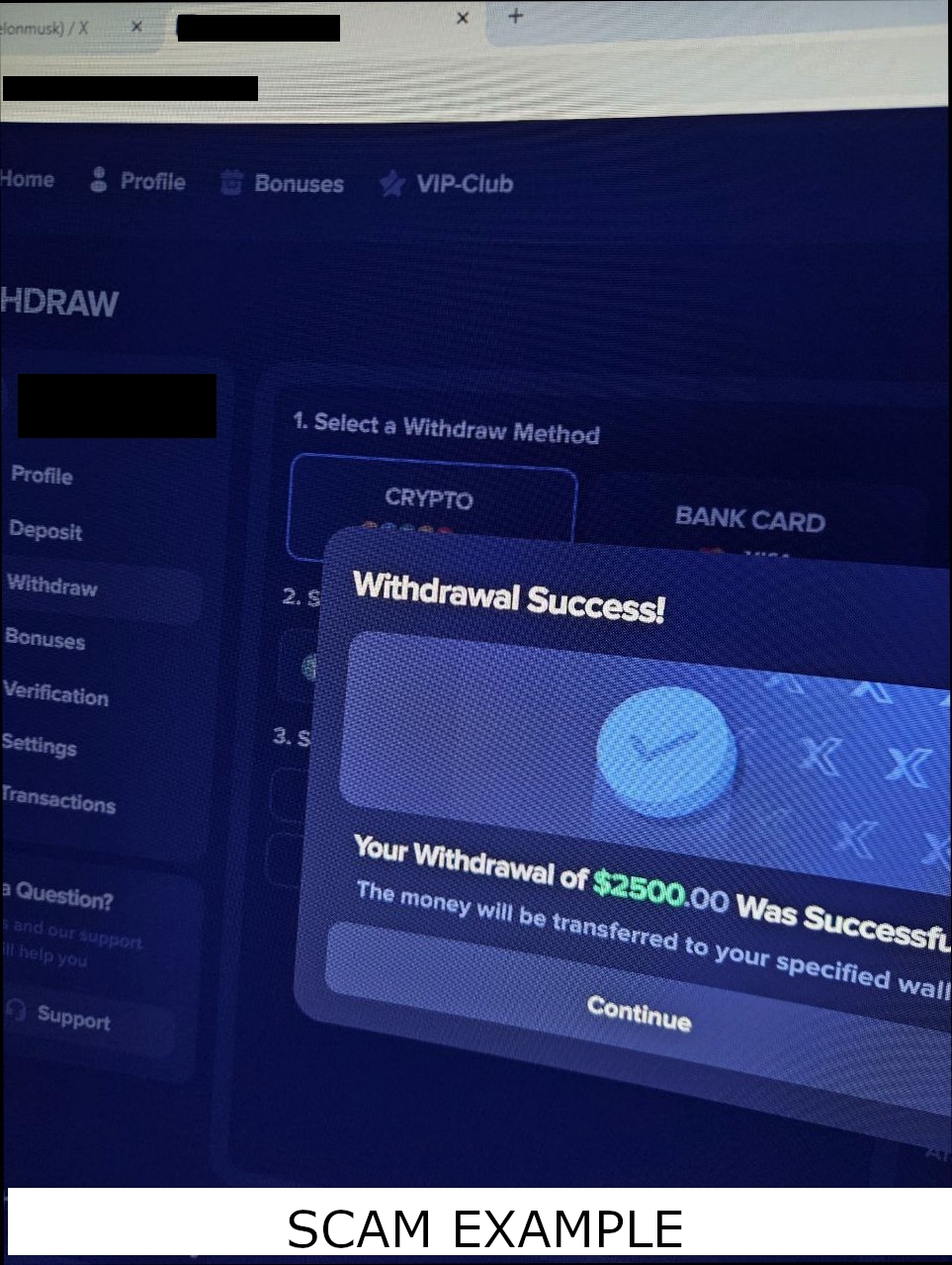
When Attackers Adapted: Moving from Exact Matching to Similarity Detection
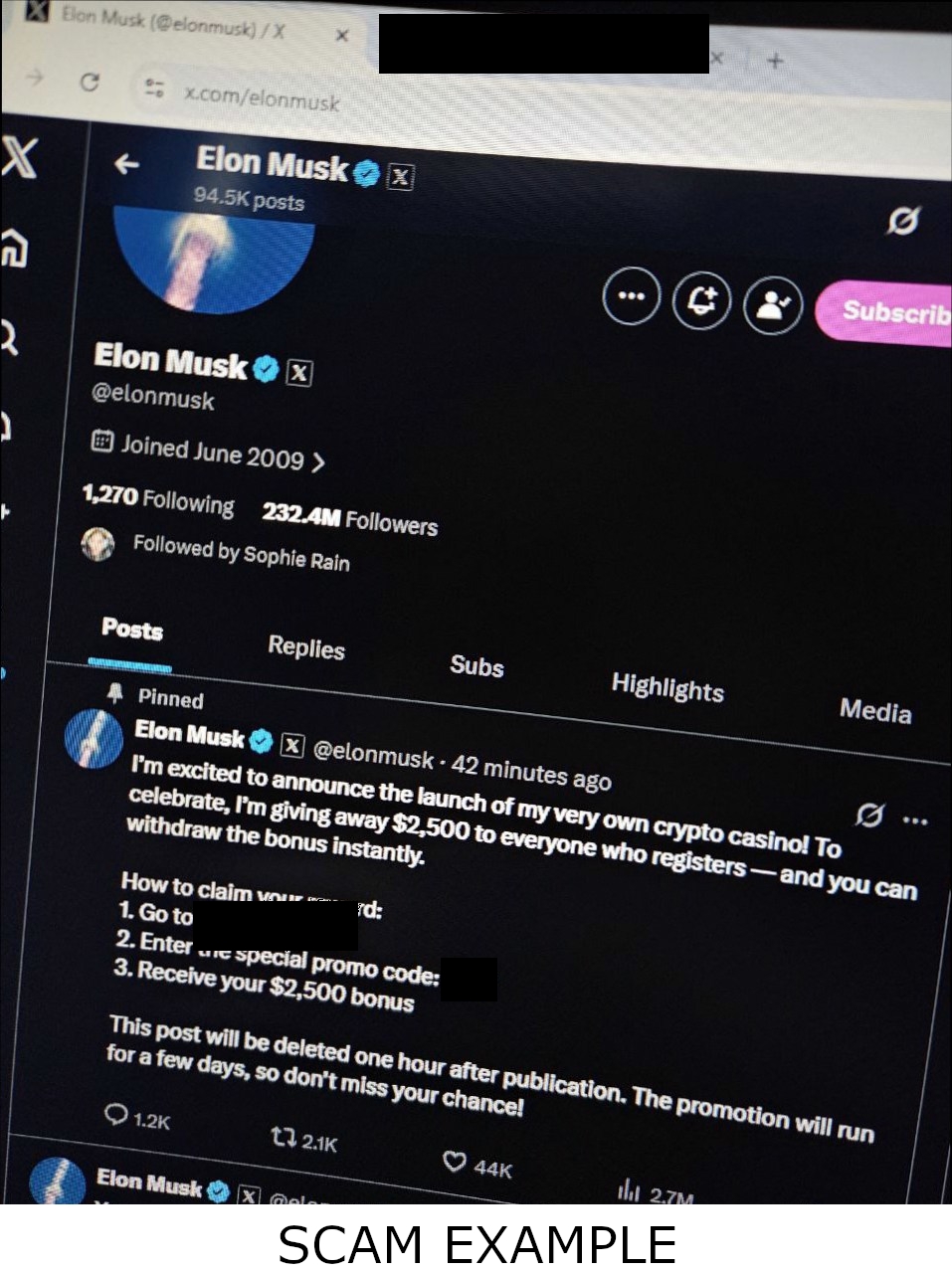
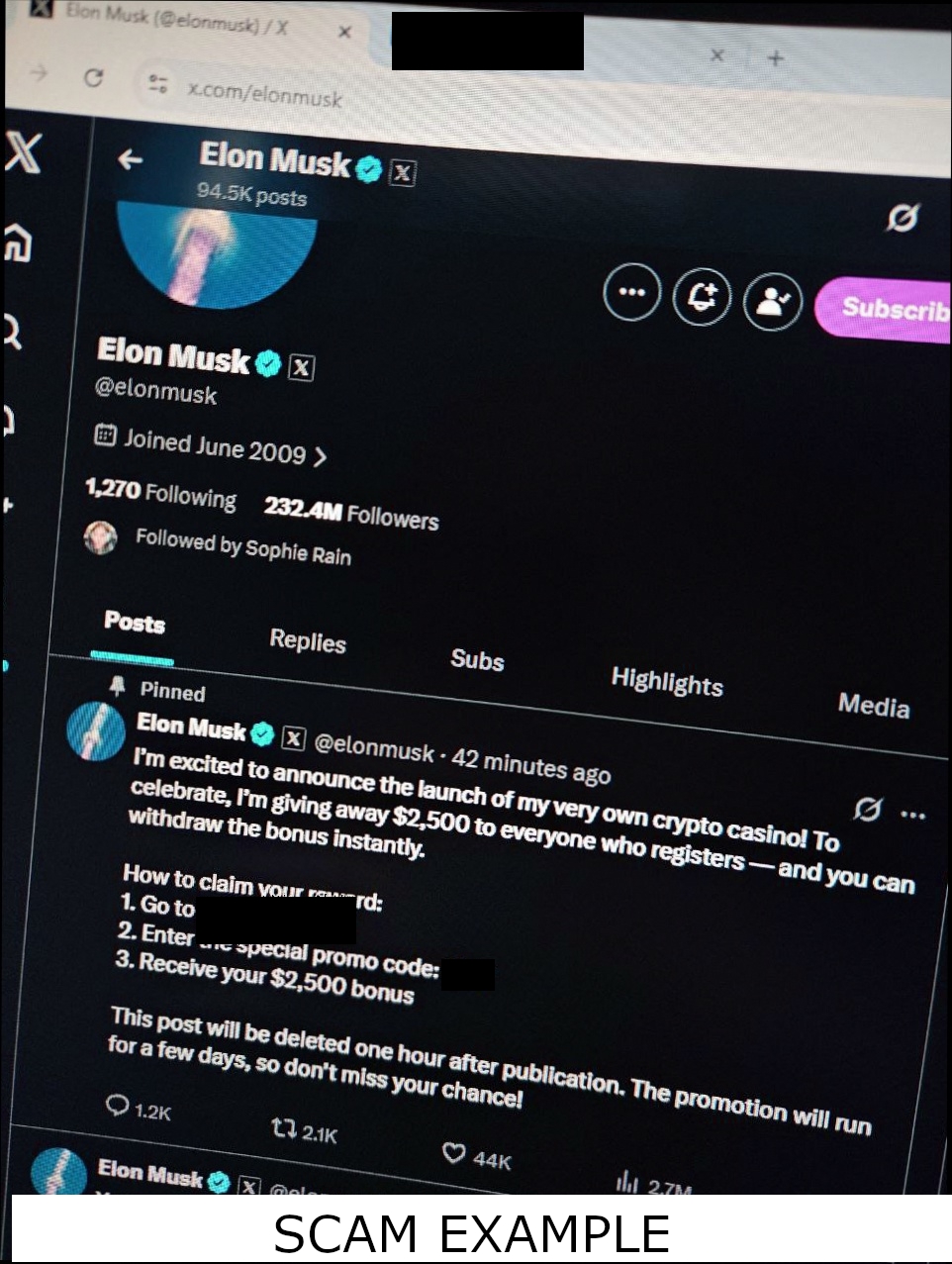
At first, exact hashing worked well. Identical scam screenshots produced identical fingerprints. But attackers quickly adapted.
The following two image sets were posted seconds apart across multiple channels:
| Original | Hue-shifted variant |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
To a human observer, they are indistinguishable. But their hashes were completely different:
| Original xxHash | Variant xxHash |
|---|---|
0x29a47899e1ac5e00 |
0xc542c6b3a7cad4b7 |
0xf3fe806dcc8e7255 |
0xd1fe4a46ea8ae48f |
0xc7be8ae78cc8d483 |
0x57676a6be2dab5b7 |
0x6e7fc0bc9e182291 |
0xd909e7a49e7866c2 |
From Rui’s perspective, these were unrelated images. This was the moment exact matching stopped being sufficient.
The pixels had changed, but the structure had not. This is precisely the problem perceptual hashing was designed to solve. Instead of hashing exact bytes, perceptual hashes encode visual structure. Small color shifts produce nearly identical fingerprints:
| Original pHash | Variant pHash | Hamming Distance |
|---|---|---|
0xc0a381c5dcded4f8 |
0xc0a383c6dcded4d8 |
4 |
0x94e29bc4a4a59aeb |
0x94e29bc4a4a59aeb |
0 |
0x9ee1e19ec2cda0b2 |
0x9ee1e196c6cda0b2 |
2 |
0x95956a69662d3627 |
0x91956a69662d6667 |
4 |
Exact hashes changed completely. Perceptual hashes barely changed at all. This allowed Rui to detect scam campaigns even when attackers deliberately modified images to evade exact fingerprint matching. Images with a Hamming distance of 10 or less can effectively be considered the same for purposes of scam campaign detection. In practice, legitimate unrelated images almost never fall within this range.
Even though this is all I’ve observed thus far, attackers aren’t strictly limited to modifying images. Text could also be altered slightly to evade exact matching. Detecting these variations requires the same principle: fingerprints that preserve similarity rather than exact identity. To handle variation in text, I introduced SimHash, a locality-sensitive hash designed so similar inputs produce similar fingerprints. Here are some examples of phrases and their respective Hamming distance from the phrase “The quick brown fox jumps over the lazy dog”, which has a SimHash of 0x2C2A1292084A8A8A
| Hamming Distance | Phrase |
|---|---|
| 0 | The quick brown fox jumps over the lazy dog |
| 8 | The quick brown fox jumped over the lazy dog |
| 9 | The quick brown fox leaps over the lazy dog |
| 5 | A quick brown fox jumps over the lazy dog |
| 9 | The fast brown fox jumps over the lazy dog |
| 10 | The quick brown fox jumps over a lazy dog |
| 9 | Quick brown fox jumps over lazy dog |
| 15 | The brown fox jumps over the dog |
| 34 | Free nitro discord gift link here |
| 33 | Completely different sentence about programming |
Quarantine and Cleanup
Initially, Rui acted based on a simple metric: if messages are equal then act. Introducing similarity-aware matching required a more nuanced decision model. In particular, some signals are stronger than others: attachments with a hamming distance less than 10 are a much clearer signal than minor variations in text. To reflect this reality I introduced a confidence rating system to Rui:
| Signal | Message Text | Image Attachments | Non-Image Attachments |
|---|---|---|---|
| Identical: xxHash | 1.00 | 1.00 | 1.00 |
| Similar: Hamming < 10 (simhash for text, pHash for images) | 0.70 | 0.95 | N/A |
| Metadata: Same file type and size | N/A | 0.60 | 0.60 |
These confidence values represent the strength of individual similarity signals. When both text and attachments are present, Rui further weights attachments at 70% and text at 30% when computing the final score. This means a text similarity confidence of 0.70 contributes only 0.21 (0.70 × 0.30) to the final decision when attachments exist. Rui computes confidence per message pair using these signals, then averages the results across recent messages to determine overall scam likelihood:
def calculate_confidence(matches: list[MessageMatch | None]) -> float:
"""
Calculate confidence score for scam detection based on message similarity.
Algorithm rationale:
- AVERAGING vs MAX: We average quality scores across all message pairs to reduce
false positives. Legitimate users sometimes spam excitedly across channels
(e.g., posting same content in both manga and anime channels). Averaging means
legitimate variance lowers the score, while consistent spam patterns maintain
high confidence.
- ATTACHMENT WEIGHTING: Attachments are weighted 70% vs content 30% because
image similarity (phash) is a stronger scam signal than text similarity.
Scammers reuse varied images more consistently than varied text.
- URL BOOST: Messages with URLs get a 30% confidence boost since scam attacks
frequently include phishing/scam links.
- NONE HANDLING: Non-matching message pairs (None in matches list) contribute
0.0 to average, further reducing confidence when user has mixed legitimate
and suspicious messages.
Returns:
Confidence score between 0.0 and 1.0, where higher means more likely scam.
"""
quality_scores = []
for match in matches:
if match is None:
quality_scores.append(0.0)
continue
content_score = match.decision.content_status.confidence if match.decision.content_status else 0.0
# Boost content score if message contains URLs (common in scams)
if match.reference.fingerprint.urlish or match.comparison.fingerprint.urlish:
content_score = min(content_score * 1.3, 1.0)
attachment_score = 0.0
if match.decision.attachment_matches and len(match.decision.attachment_matches) > 0:
attachment_confidences = [am.status.confidence for am in match.decision.attachment_matches]
attachment_score = sum(attachment_confidences) / len(attachment_confidences)
if match.decision.attachment_matches and len(match.decision.attachment_matches) > 0:
# Weight attachments higher than content when attachments exist
combined_score = 0.7 * attachment_score + 0.3 * content_score
else:
# No attachments, rely purely on content similarity
combined_score = content_score
quality_scores.append(combined_score)
return sum(quality_scores) / len(quality_scores)
The exact values—whether for individual signal confidence, signal weighting, or action thresholds—are heuristic, chosen to reflect the relative strength of each signal and refined through observing real scam behavior. Image similarity is a stronger indicator than text similarity, while metadata matches provide weaker but still useful corroborating evidence.
However, no detection system is perfect—false positives and false negatives are inevitable. Rui treats this as a fundamental design constraint rather than an edge case. It is designed for containment, not autonomous enforcement. Instead of issuing automated kicks or bans, it quarantines suspicious users via temporary timeouts and defers final judgment to human moderators.
What Rui will do automatically:
- Delete detected scam messages to prevent further spread
- Upload a copy of the message to a moderator-facing audit channel
- Temporarily timeout the user to contain potentially malicious activity
Final enforcement decisions remain with the server’s moderators.
The Funding Problem
Running Rui isn’t free. Here is a breakdown of Rui’s running costs:
- Cloudflare Domain Name Registration: $27.18/year (est $2.27/mo)
- Instance 0 - with automated backups: $7.20/month
- Instance 1 and each future instance: $6/mo
This means Rui needs to generate at least $15.47/month to cover infrastructure costs, in addition to compensating the time spent developing and maintaining it.
The “Bites” System: Attempting Usage-Based Pricing
My first instinct was to price Rui proportionally to resource usage. Rui’s primary marginal per-guild cost is memory. Each guild maintains a rolling message buffer for similarity detection, and the size of that buffer scales with message rate and queue duration. A server that receives more messages, or retains them longer, consumes proportionally more RAM.
Early measurements suggested a typical guild averaging 3 messages per minute with a 30-second queue used roughly 10 MB of memory. With my infrastructure costing $6/month for 1 GB of RAM, that implied a marginal cost of roughly $0.06 per guild per month.
Charging fractions of a dollar per guild would be impractical, so I introduced an abstraction called a bite. One bite represented one message held in Rui’s in-memory queue. Since the number of messages in memory at any moment is approximately:
This provided a simple, usage-based unit that scaled naturally with load. Instead of billing directly for RAM, I could allocate bites and price them in larger, more manageable quantities. This allowed a subscription to fund multiple guilds, with bite limits determining overall capacity.
In theory, this allowed Rui’s pricing to scale proportionally with actual infrastructure usage. In practice, the model depended heavily on accurate memory measurements and their interpretation.
Discovering I Was Wrong About Memory Usage
Further investigation revealed that my initial memory estimates were off by orders of magnitude. The message queues themselves consumed far less memory than expected—likely closer to kilobytes than megabytes. The dominant costs were fixed overhead: the runtime, libraries, database connections, and baseline infrastructure required to operate reliably.
This meant Rui’s marginal cost per guild was effectively negligible. A pricing model built around per-guild memory usage was optimizing for a resource that wasn’t meaningfully scarce.
More importantly, the complexity wasn’t buying anything. Even if the estimates had been accurate, the resulting costs would still have been measured in cents. The precision of the model created the illusion of economic significance. In reality, the per-guild cost was too small to meaningfully influence pricing decisions.
I ultimately abandoned the bite system. It was a valid, dimensionally correct abstraction—but it solved the wrong problem. Rui’s real costs were driven by fixed infrastructure, redundancy, and operational reliability—not marginal per-guild memory usage. This realization forced me to rethink Rui’s funding model.
Rethinking Premium: Value Beyond Usage
The bite system made sense for the same reason the multithreaded architecture had made sense earlier. It was precise. It measured something real. It provided a clean abstraction grounded in a physical resource.
And, like the threaded architecture, it was solving the wrong problem.
The bite model assumed that Rui’s cost scaled with how much memory each guild consumed. That assumption was reasonable. Scam detection requires maintaining rolling message windows, and memory usage grows with message volume and retention time. Bites provided a way to measure that growth exactly.
But when I measured Rui’s actual memory usage in production, the results didn’t match the model.
The rolling message windows consumed very little memory. The dominant costs came from Rui itself: the runtime, persistent service connections, coordination infrastructure, and the baseline resources required for Rui to remain continuously online. Whether Rui protected one guild or one hundred, most of its cost remained unchanged.
This was the same mistake I had made with the threaded architecture. Threads had improved responsiveness by isolating workloads, but they worked against the structure of Discord’s gateway. They optimized for separation when the real constraint was coordination. The bite system made the same kind of error. It optimized for measuring usage when usage was not the defining constraint.
Rui’s cost was not driven by how much it processed. It was driven by the fact that it existed at all.
Once that became clear, the question was no longer how to meter Rui’s usage, but what premium should represent.
Core scam detection would remain available to everyone. Rui’s primary purpose is protection, and that protection is most effective when it is widely deployed. Premium would instead provide additional capabilities aligned with Rui’s investigative and operational role:
- Forensic Logging. Recently deleted messages are fingerprinted and preserved, ensuring missed attacks leave behind evidence that can be analyzed even after cleanup.
- Investigation and Response. When a sophisticated scam campaign bypasses automated detection, I can analyze forensic evidence, reconstruct the attack, and refine Rui’s detection to prevent similar attacks in the future.
- Support for the Protection Network. Premium subscriptions fund the infrastructure and operational continuity required to keep Rui online and improving.
These do not replace Rui’s core function. They extend it. Automated detection stops most attacks, but investigation, forensic preservation, and continuous improvement ensure that Rui becomes more effective over time.
Like the threaded architecture before it, the bite model was a clean abstraction that optimized the wrong constraint. Moving beyond it allowed Rui’s design—and its premium offering—to reflect how the system actually operates.
Operating Rui as Real Infrastructure
Once premium was reframed around operational continuity, the implications extended beyond architecture. Accepting payments meant accepting responsibility in a domain I had never operated in before—not technical responsibility, where the constraints are legible and the feedback is immediate, but legal and structural responsibility, where doing things correctly is harder to verify and the cost of getting it wrong is less predictable. Up to this point, Rui had existed entirely as a personal project—informality that was fine when the only person depending on it was me, and wasn’t fine when other communities would be paying to rely on it.
I tried to do things the proper way. I established JCall Engineer LLC as the operating entity, obtained an EIN, evaluated payment processors, and settled on Stripe after PayPal’s API proved too inflexible for the subscription behavior Rui required. The legal and operational work was slow and unfamiliar. I had help drafting the terms of service and privacy policy, but I read through every line myself multiple times, wanting to make sure I understood what I was agreeing to and what I was asking others to agree to. It was not my forte—I am more comfortable reasoning about hash functions than liability clauses—but the same instinct that drives me to get the technical details right wouldn’t let me treat this any differently. If people were going to depend on Rui, I owed it to them to be as careful here as anywhere else.
What’s Next for Rui
One area I have considered is maintaining a corpus of fingerprints for known scam campaigns. This would allow Rui to quarantine scams immediately, rather than waiting for them to spread across multiple channels before detection confidence rises. However, this introduces new challenges. Such a system would require careful curation, safeguards against false positives, and a reliable mechanism for keeping the dataset accurate and up to date. I have ideas, but nothing concrete enough that I am confident in deploying it yet.
More broadly, I hope to expand Rui into as many communities as possible so it can establish a network of protection. Scammers who target one server could be identified and contained across the entire network, limiting their ability to reuse the same campaigns elsewhere. This has always been the long-term goal of Rui’s scam guard: not just to react to attacks, but to make them ineffective.
If you’d like to be part of that network, Rui is free to add to your server.
In a sense, the ideal outcome is for Rui to make itself obsolete. A world where these scam campaigns no longer succeed is one where Rui is no longer needed. That may not be a conventional business objective, but for those of us who rely on Discord every day, it is the best outcome we could hope for.